Starofus
你好呀,我是Sans
Impala多线程强化学习总结
在visdoom环境中利用多线程算法impala加速强化学习,用有限的家用机器资源训练出实战级别的rl agent

本次的代码:https://github.com/mrzhuzhe/ViZDoom/tree/master/mytest
1. 动机:
- 1. 训练一个实战级别的 强化学习 agent , 用这个pipline为baseline方便以后参加比赛
- 2. 强化学习可以在自监督部分对比计算机视觉,计算机视觉的residul连接和注意力也是rl编码器部分不可缺的模块,可以互相加深理解
- 3. 这个pipline要也能够用在工业生产的机器人控制上
2. 目标:
- 1. 【通用】不能使用过多的trick和特征工程
- 2. 【快】要训练的尽可能的快
- 3. 【性能】agent在任务上的稳定性和性能上限要能够达到sota
- 4. 【self play】要使用self play
目前的进展:
- 1. 【通用】在vizdoom等任务上,输入只使用了
"160x100的游戏图像" + "游戏面板信息"(例如:生命值和弹药量) - 2. 【快】我自己实现的impala 1e7 step 只需 2 小时 30分, 如果使用更快的rlpyt架构 1e7 step 只需30分钟 注:此处硬件配置见 “4. 实验设计”
- 3. 【性能】在battle1 地图中 1e7 step 已经学会 “向敌人开枪” "拾取医药箱“ ”拾取子弹“ 等瓶颈, 并且探索到了 ”躲避“ ”堵口“ “360度旋转” ”冲“ 等多种策略
- 4. 【self play】在doom的决斗地图上进行了 4e8 step 的自己和自己决斗,已经学会了 “探路” “躲避敌人攻击” “拾取重机枪” “拾取远程霰弹枪” “抢占关键点” 等极其复杂的游戏策略
3. 视频演示:
多样化策略:(输入只有图像)
- 1. 躲藏
- 2. 转圈
- 3. 堵口
输入 = 图像 + 游戏面板信息
- 1. 对拾取弹药和医药箱做0.5的奖励 => 在之前策略基础上会拾取弹药和医药箱
4. 相关工作:
# 最初看到kaggle上 lux-ai2021比赛中的冠军方案就是基于Impala,他的思路是
- 1. 用Impala scale up 和加速训练 impala 论文 , 具体实现用的是 torchbeast
- 2. 参照alphastar(因为lux这个比赛其实和starcraft挺像),也加入了td-lambda和upgo的辅助loss
这个可以参照alphastar论文 deepmind alphastar
【TODO】这里 td-lambda 起到的作用应该是 critical loss 计算时考虑全局而非原本 vtrace 只考虑比较好的rollout
【TODO】upgo 是类似ppo防止优化时方差太大 - 3. 先训练层数少的小模型,再用teacher kl散度把训练好的小模型向大模型蒸馏
- 4. 用 resnet 等cv的sota 替换原本的特征编码器
# 更新的方案
其实现在还有一些基于vtrace的更新的方案,速度和减少开销在impala上还有很大的提升,例如
- 1.dd-ppo https://arxiv.org/abs/1911.00357 rlpyt 的impala ppo 实现 :https://github.com/astooke/rlpyt
- 2.sample factory https://github.com/alex-petrenko/sample-factory 综合了最新的方案,速度达到了最快
- 3.seed rl https://github.com/google-research/seed_rl 修复了impala的几个不合理的地方
- 4.r2d2 https://openreview.net/pdf?id=r1lyTjAqYX 利用lstm来进行q-learn过程
5.impala的技术选型和意义:
impala的整体结构
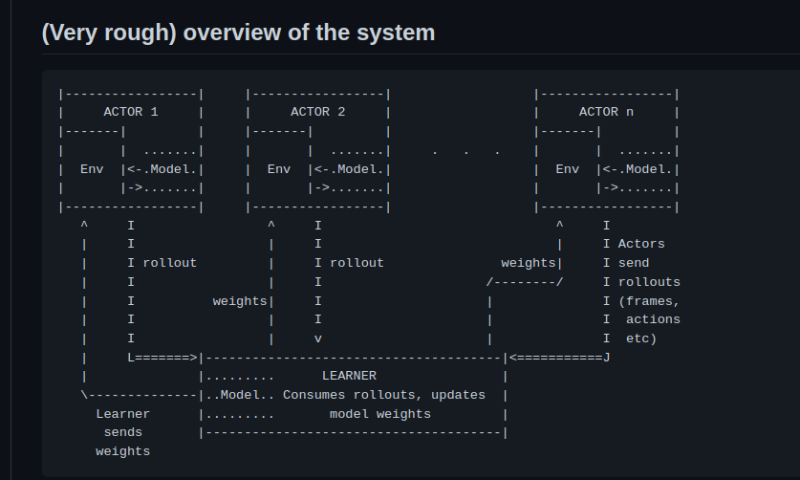
- on policy/off policy: 目前impala的实现都是用多线程产生replay buffer,都是off policy的
- q-learning/actor-critic: 采用基于vtrace的 actor critic policy梯度法
3个LOSS的意义:
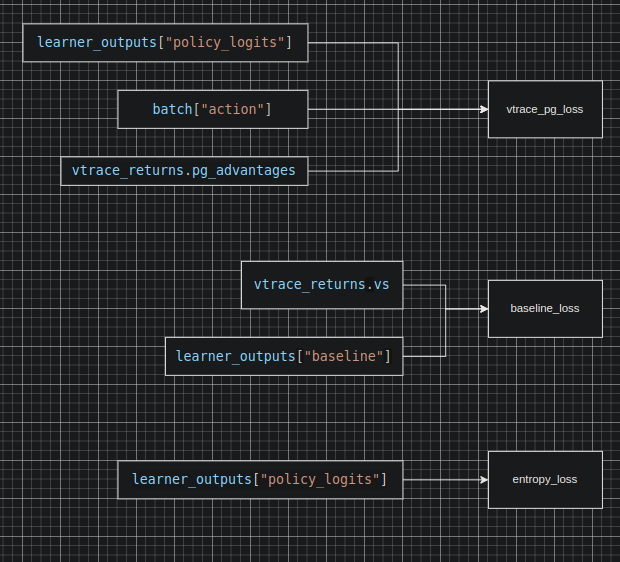
- policy_pg_loss 鼓励收益大的选择概率大, 需要critic估计的收益来作为基准来更新梯度
- entropy_loss 这个loss是一个负系数loss 所以优化方向为 尽可能的熵变大(更倾向于探索),但是随着训练熵本身会不变小(越来越保守),所以如果policy loss优化不下去了,熵就会变大,鼓励探索
- baseline_loss critic_loss, 估计的收益和实际收益的L2范数
vtrace的作用和意义
- actor-ctric在off-policy情况下的不足: 如果仅使用原始的replay buffer 因为 actor critic 中 actor 和 critic 中只有ctritic 在学习, actor的策略是滞后的,如果全学习所有actor就会导致学习引入大量低质量样本的噪声
visdoom battle 环境下 PPO 的学习曲线:抖动更小 1M step 55分钟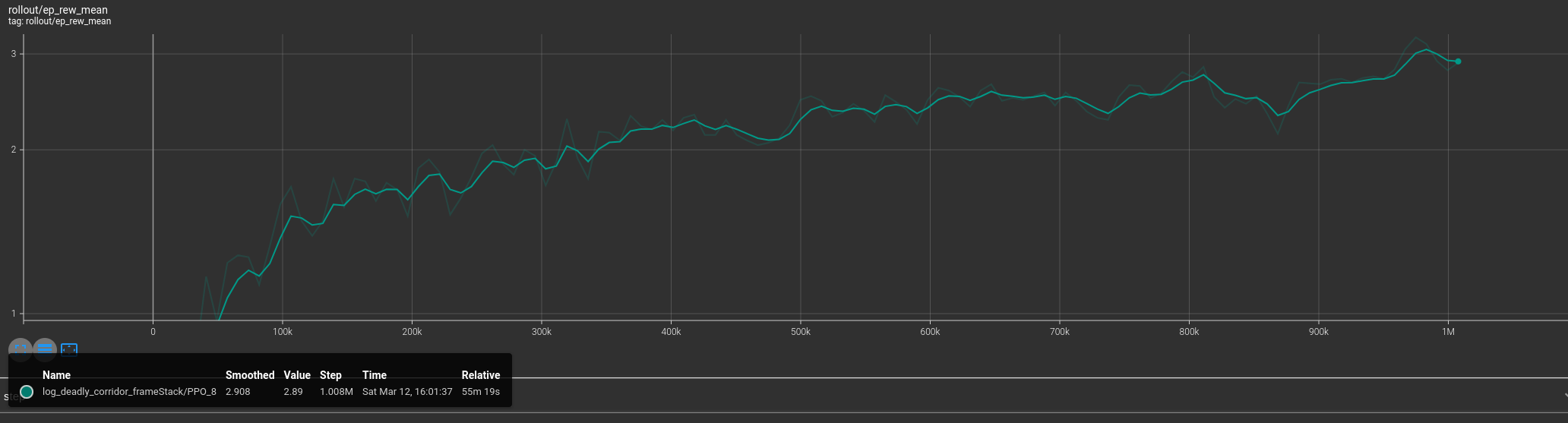
Impala Off policy actor-critic的学习曲线:抖动更大 1M step 18分钟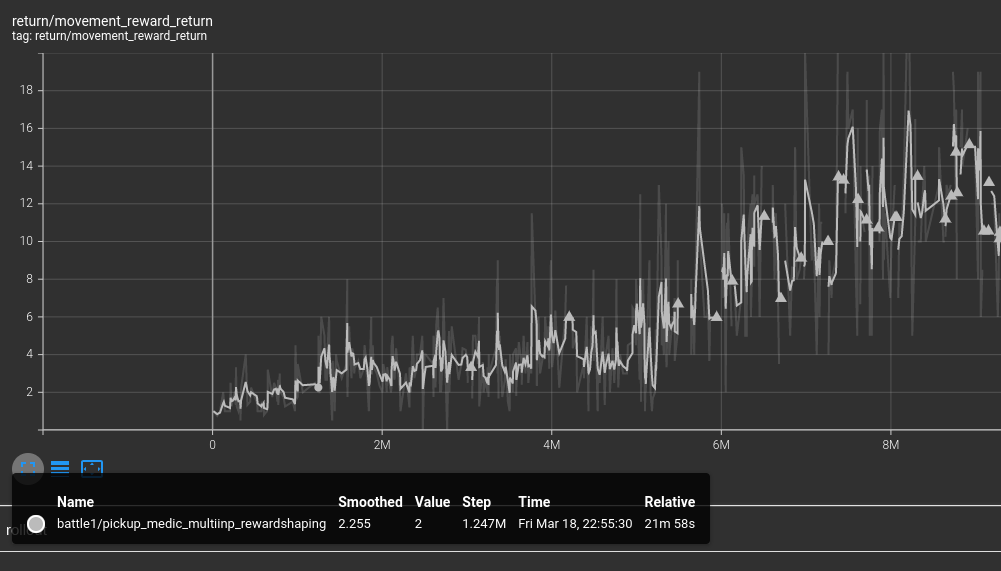
- general advance estimate: 所以vtrace对训练样本进行了一次重要采样,这个操作相当于只学习actor中表现比较好的情况
硬件环境
- 使用gpu actor时: 2核cpu 18g内存 7g显存 cuda idle占用60%左右 这里gpu存在一个内存占用过高的问题seed rl中有解决方案
- 使用cpu actor时: 8核cpu 8g内存 7g显存 cuda idle占用10%左右 训练速度其实和使用gpu一样
6. 实验:
实验设计:
- 1. 【单线程/多线程】: 对比了PPO和Impala训练相同任务的情况,ppo慢且稳定,impala快但是波动大
- 2. 【LSTM层】,因为瓶颈不在这,所以对速度稳定性收敛速度都影响不大
- 3. 【td-lambda】计算baseline loss(critic loss) 时使用 td-lamda.adv 而非 vtrace.adv 似乎使训练更稳定了,收敛速度也变快了
- 4. 【upgo】 收敛速度似乎变慢了
- 5. 【teacher kl】, 表现符合预期,不过模型容量是不是因为蒸馏提升了上限还有待观察
- 6. 【更改loss的系数】 因为我最后有四个 loss policy_pg entropy baseline_loss upgo_policy改这四个loss的系数对结果影响挺大的,不过因为我只训练了2e7这四个loss的调参都没有对突破瓶颈有帮助
- 7. 【multi input】 把游戏面板信息加入到训练中
这个对前期突破瓶颈学得 "拾取医药箱“ ”拾取子弹“ 影响极大
其实这也很符合直觉,毕竟如果让电脑学会看游戏面板,还能理解到游戏中交互和面板的关系,只依靠最后的reward确实是很难的
- 8. 【reward shaping】 虽然我给agent 最终的reward设定是 杀死一个敌人1分 拾取医疗包 0.5分 子弹 0.5 分 对结果影响如预期那么大,不过按照网上的说法,这个只在训练早期作用很大
- 9. 【vec env 和 frame stack】: vec env 可以极大的的增加对cpu的利用, frame stack 和 frame skip 可以略微减少过于重复的临近帧,节约资源
- 10. 【seed rl 或 sample factory】 在rlpyt和seed rl论文中,提到
impala中去中心化actor critic中因为policy在actor产生,必须把learner向policy中多次复制,
因此如果把原本acrtor中的model取消把actor 分为 rollout worker (无model通过消息队列和policy worker通信获取行动规划) 和 policy woker (只存在gpu中)
就能大幅度减少gpu和cpu中重复复制模型的通信成本,这个改动能带来近百分之八十的效率提升,能在原本加速基础上带来几乎五倍的加速
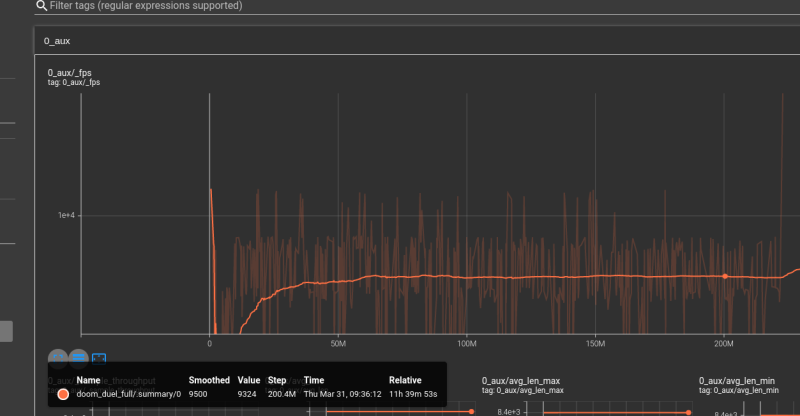
如上图 2e8 step只需12小时
- 11. 【self play】doom的任务中,因为对手操作本身就完全不可见,self play 只需把对手的rollout replay也一起加入训练batch即可,需要注意的是有的人物需要把对手视角一起加入observe,让agent可以在执行策略时考虑对手的反应。
- 12. 【scale up】doom battle 只对抗冲向自己的怪物 doom deul 需要对抗能跟自己一样行动的对手,需要的step增加了约40倍
- 13. 【演化算法-PBT】使用演化算法popolation base training 同时训练多个(2个)agent,如果其中有一个agent效果和最好的结果相差百分比达到阈值,则改变比较差的那个agent的参数,以增强agent的多样性
- 14. 【encoder换resnet】常规操作
实验中观察到的现象:
- 1. 【各种方法对结果影响】:
目前测下来 teacher force distill 的影响对大
大于 td lambda uogo等辅助loss
再其次是 lstm
影响最小的是 演化算法
- 2. 【self play的不稳定】: self play中agent更容易过拟合,容易两个agent都陷入实际场景中不会出现的情况
- 3. 【瓶颈】: 如果环境中存在明显的局部最优解 或者难以学到的瓶颈,则这些瓶颈会体现在训练曲线上,形成陡增
7. 遇到的问题:
- 1. 【RL过拟合】: 如演示,agent很容易陷入到局部最优中,当然rl的td学习的的贝尔曼方程就是只保证优化到局部最优的
- 2. 【loss的意义】: 用 actor-critic algorithem原作理解下来critic loss 用来估计value函数, policy loss, 用ctric产生的alue来近似模拟梯度
- 3. 【瓶颈确认】: 到底是调参在起作用还是我的结构改动在起作用呢?
- 4. 【启发式先验】启发式先验知识依然对突破瓶颈能起到类似residule connect一样关键的作用
8. 结论:
1. 【RL kick start启动】: 因为前期往往存在很多“瓶颈行为”需要学习,所以rl训练往往存在前期收益十分平缓,但是解决某一关键“常识”的学习后收益立即陡增的情况:例如pingpong游戏中的“接球”这一行为
要解决这个问题目前有几条思路
- (1) 环境简化: 例如 doom这个环境中agent如果要学习认识游戏面板上的数字,需要非常久的时间,所以直接把游戏面板信息作为结构化数据输入给agent就会节约大量的学习时间
- (2) reward shaping: 前期对一些关键行为进行特征工程的诱导,人为奖励一些行为,例如接近目标等作为辅助reward,会很大的帮助agent学习“瓶颈行为”
- (3) 模仿学习: 模仿学习或者行为克隆因为只学习目前行为和目标行为的交叉熵,所以非常的省计算资源,例如lux比赛中就有大量的人使用模仿学习 https://www.kaggle.com/c/lux-ai-2021/discussion/294098,
而且按照alphastar的说法,模仿学习可以让alphastar到大师等级 - (4) teacher force 如果已经有一次成功的训练,可以用这个模型来蒸馏后续的模型,蒸馏可以很快的让student模型到达teacher模型的精度 https://arxiv.org/pdf/1803.03835.pdf
2. 最后贴一下的,doom duel 任务的演示视频
只训练了 1e7 steo的情形,会冲向敌人但是,只会360度旋转开枪, 或是堵口
训练了 4.5e8 step 的情形, 已基本可以达到普通人水平
9. 未解决问题:
- (1) RL策略的广度,目前看下来似乎包括alphastar都只能探索kick start定下的“基调”附近的策略,如果出现没有见过的情况,几乎无法处理,其实策略搜索的广度是很有限的
- (2) 新的rl算法都试图提升探索的效率,或者降低噪声让收敛的上限上升,这个很难界定
- (3) 目前我对于loss对表现的影响意义还有待提升
- (4) 如何提升self play对抗学习的多样性和稳定性?
- (5) 如何发现性能中的瓶颈,是env buffer 架构 还是model形成了性能瓶颈呢?
- (6) model base 和 policy search 方法还需要测试