Starofus
你好呀,我是Sans
【HPC 05】CPU 和 CUDA 的 GEMM 实现
2023-5-12
CPU 和 GPU 的 GEMM 实现
代码:https://github.com/mrzhuzhe/riven
1. 概述
BLAS Basic Linear Algebra Subprograms 就是指线性代数基础库,内容是矩阵乘法在多种硬件如x86和ARM/CPU/GPU上的实现,一般会作为其他库的底层模块来调用
市面上比较好的实现有openBLAS/intelMKL/Eigen等
这个最主要的意义是:理解矩阵成法可以用硬件的哪些特性来优化,总结优化方法的模式pattern,可以广泛的推广用在其他定制算子开发设计中
本次实现了
- 1. CPU 的 GEMM: SIMD分块 > 内存pack分块 > AVX 和 SSE 指令集的细粒度调优 > 汇编指令优化
- 2. GPU GEMM 的优化方向 shared memory > stride > warp 原语
- 3. CPU 和 GPU 卷积 navie 实现
这是我的Cpu信息
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 167
Model name: 11th Gen Intel(R) Core(TM) i9-11900 @ 2.50GHz
Stepping: 1
CPU MHz: 2500.000
CPU max MHz: 5200.0000
CPU min MHz: 800.0000
BogoMIPS: 4992.00
Virtualization: VT-x
L1d cache: 384 KiB
L1i cache: 256 KiB
L2 cache: 4 MiB
L3 cache: 16 MiB
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabl ed via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __ user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional , RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts ac pi mmx fxsr sse sse2 ss ht tm pbe syscall n x pdpe1gb rdtscp lm constant_tsc art arch_p erfmon pebs bts rep_good nopl xtopology non stop_tsc cpuid aperfmperf tsc_known_freq pn i pclmulqdq dtes64 monitor ds_cpl vmx smx e st tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid s se4_1 sse4_2 x2apic movbe popcnt tsc_deadli ne_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_s ingle ssbd ibrs ibpb stibp ibrs_enhanced tp r_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erm s invpcid mpx avx512f avx512dq rdseed adx s map avx512ifma clflushopt intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec x getbv1 xsaves dtherm ida arat pln pts hwp h wp_notify hwp_act_window hwp_epp hwp_pkg_re q avx512vbmi umip pku ospke avx512_vbmi2 gf ni vaes vpclmulqdq avx512_vnni avx512_bital g avx512_vpopcntdq rdpid fsrm md_clear flus h_l1d arch_capabilities
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 167
Model name: 11th Gen Intel(R) Core(TM) i9-11900 @ 2.50GHz
Stepping: 1
CPU MHz: 2500.000
CPU max MHz: 5200.0000
CPU min MHz: 800.0000
BogoMIPS: 4992.00
Virtualization: VT-x
L1d cache: 384 KiB
L1i cache: 256 KiB
L2 cache: 4 MiB
L3 cache: 16 MiB
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabl ed via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __ user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional , RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts ac pi mmx fxsr sse sse2 ss ht tm pbe syscall n x pdpe1gb rdtscp lm constant_tsc art arch_p erfmon pebs bts rep_good nopl xtopology non stop_tsc cpuid aperfmperf tsc_known_freq pn i pclmulqdq dtes64 monitor ds_cpl vmx smx e st tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid s se4_1 sse4_2 x2apic movbe popcnt tsc_deadli ne_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_s ingle ssbd ibrs ibpb stibp ibrs_enhanced tp r_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erm s invpcid mpx avx512f avx512dq rdseed adx s map avx512ifma clflushopt intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec x getbv1 xsaves dtherm ida arat pln pts hwp h wp_notify hwp_act_window hwp_epp hwp_pkg_re q avx512vbmi umip pku ospke avx512_vbmi2 gf ni vaes vpclmulqdq avx512_vnni avx512_bital g avx512_vpopcntdq rdpid fsrm md_clear flus h_l1d arch_capabilities
2. 相关工作
为什矩阵乘法这么重要:
- 因为矩阵乘法是 卷积/线性方程度直接求解/迭代求解的基础
用途
- 卷积:信号处理FFT
- 解线性微分方程: 最优化问题/深度学习/动力学等
需要大量用到计算机体系结构的知识:
- Lcache 寄存器
- 内存排布 和 预取
- x86 x64指令集 的各自特性
- 异构众核(GPGPU)的 各种特性
- tensor-core等定制计算单元【TODO】
- 使用perf工具确认性能瓶颈【TODO】
总结下来就是如何把计算机CPU芯片的计算单元都利用到极限
3. 实验设计
CPU 下 GEMM
这一部分主要参考了白牛的文章OpenBLAS gemm从零入门
后面汇编优化的部分参考了https://github.com/flame/blislab的
https://www.mathematik.uni-ulm.de/~lehn/apfel/sghpc/gemm/
注意这个站点在HTTPS下一部分资源加载不出来,我搬迁到了github page上
https://mrzhuzhe.github.io/ulmBLAS-sites/
- 1. 循环跨步:一个循环中进行多次操作 4次riven/gemm/src/MMult5.c
- 2. 使用寄存器 减少内存读取riven/gemm/src/MMult6.c
- 3. 4x4分块,并且手动开启SIMD指令riven/gemm/src/MMult16.c
- 4. 对矩阵大小进行z轴分块,注意必须先把分块好的矩阵存下来访问才能触发L1缓存 注意这个函数:PackMatrixAriven/gemm/src/MMult17.c
另外注意pack其实只需pack一次,如果每次都pack反而会引起性能下降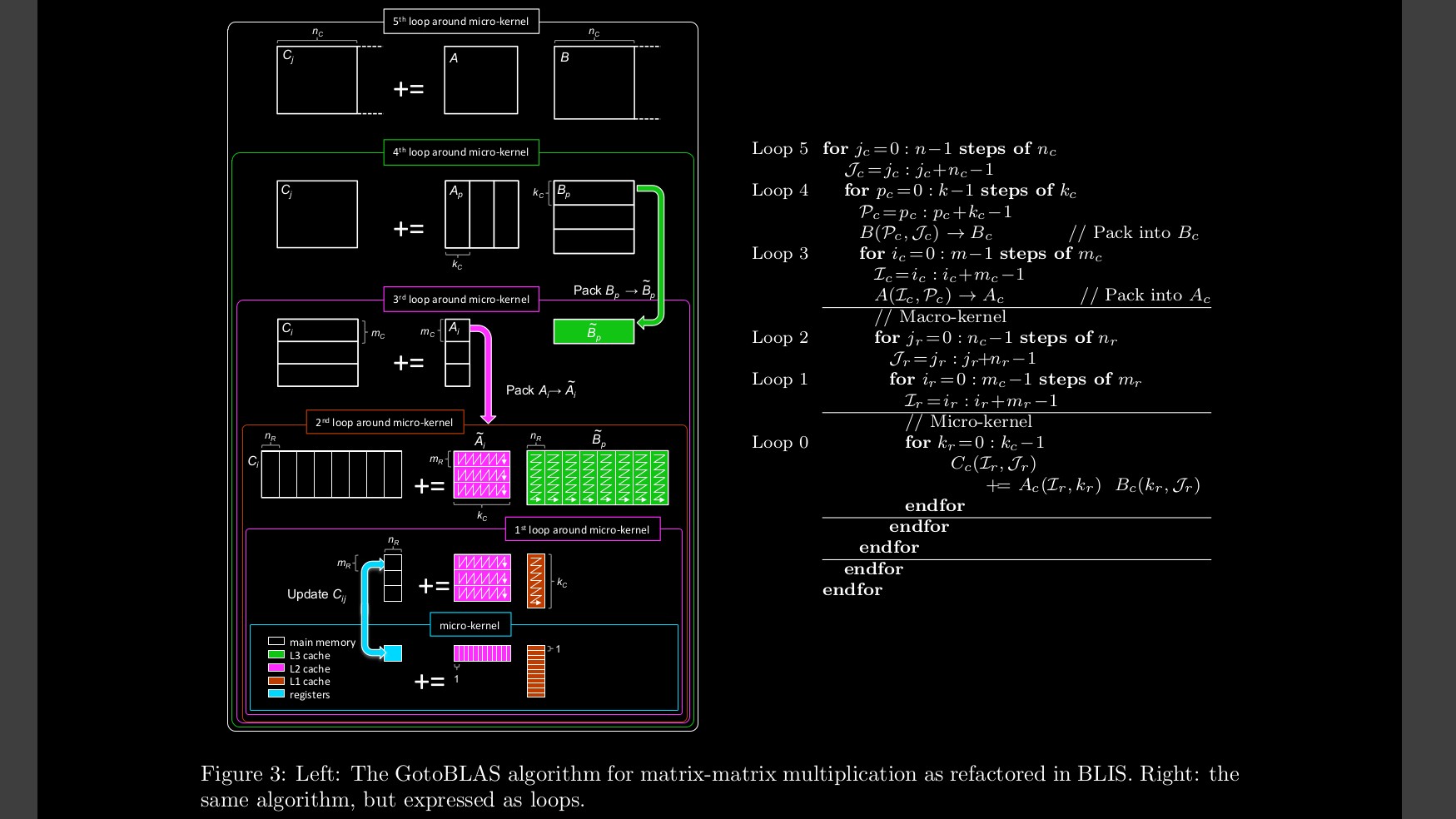
Pack完的矩阵 比如 256 X 16 会被打包传入一个函数内计算(我们约定此函数为macro_kernel)
然后在在macro_kernel 内部再进行一次拆分 进一步拆分为针对SIMD的 8x4矩阵的更小函数(我们约定针对SIMD的函数为micro_kernel)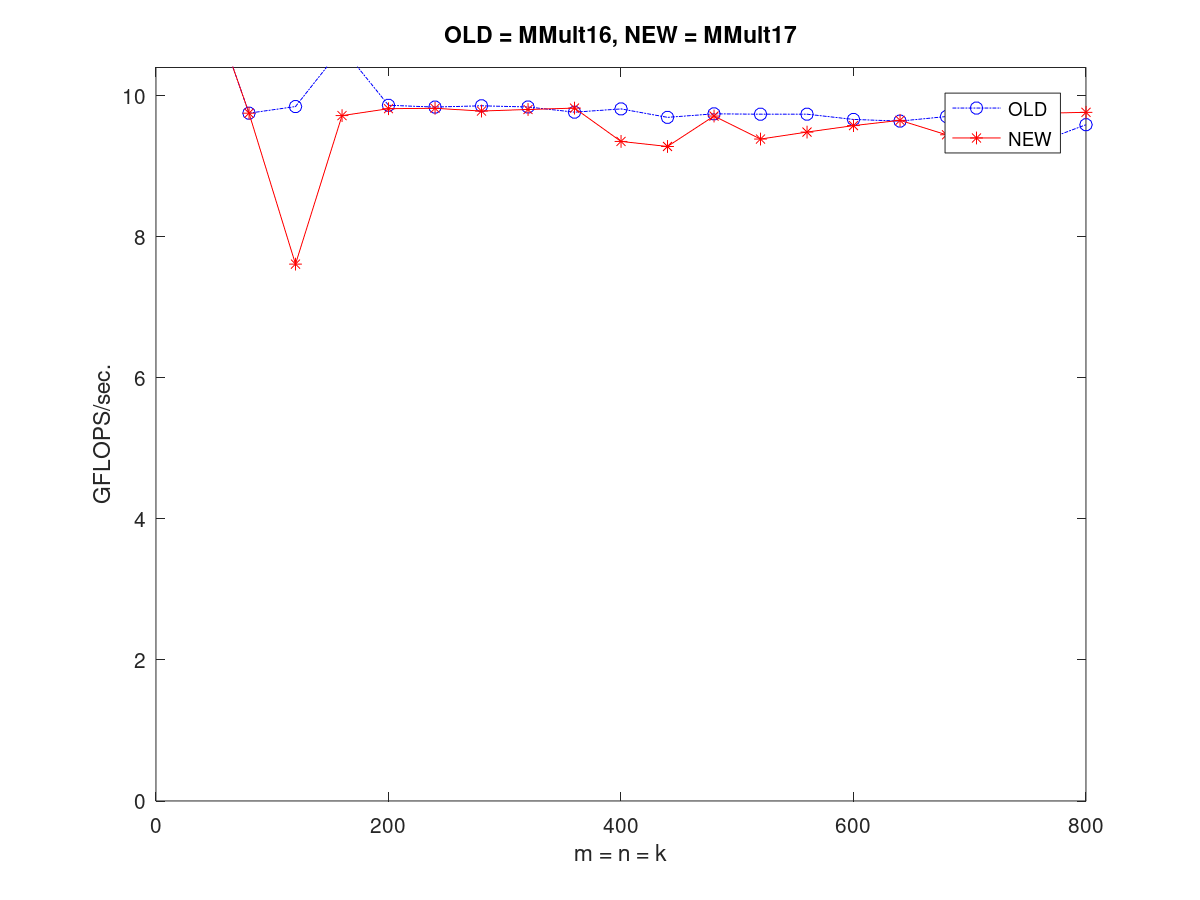
注意这个版本的性能只有10GFLOPS左右 - 6. MMult22_avx 改为 avx 实现 从 4x4 矩阵改为 8x4矩阵 并且修改了之前的一个bug store矩阵也改为用avx 指令来store
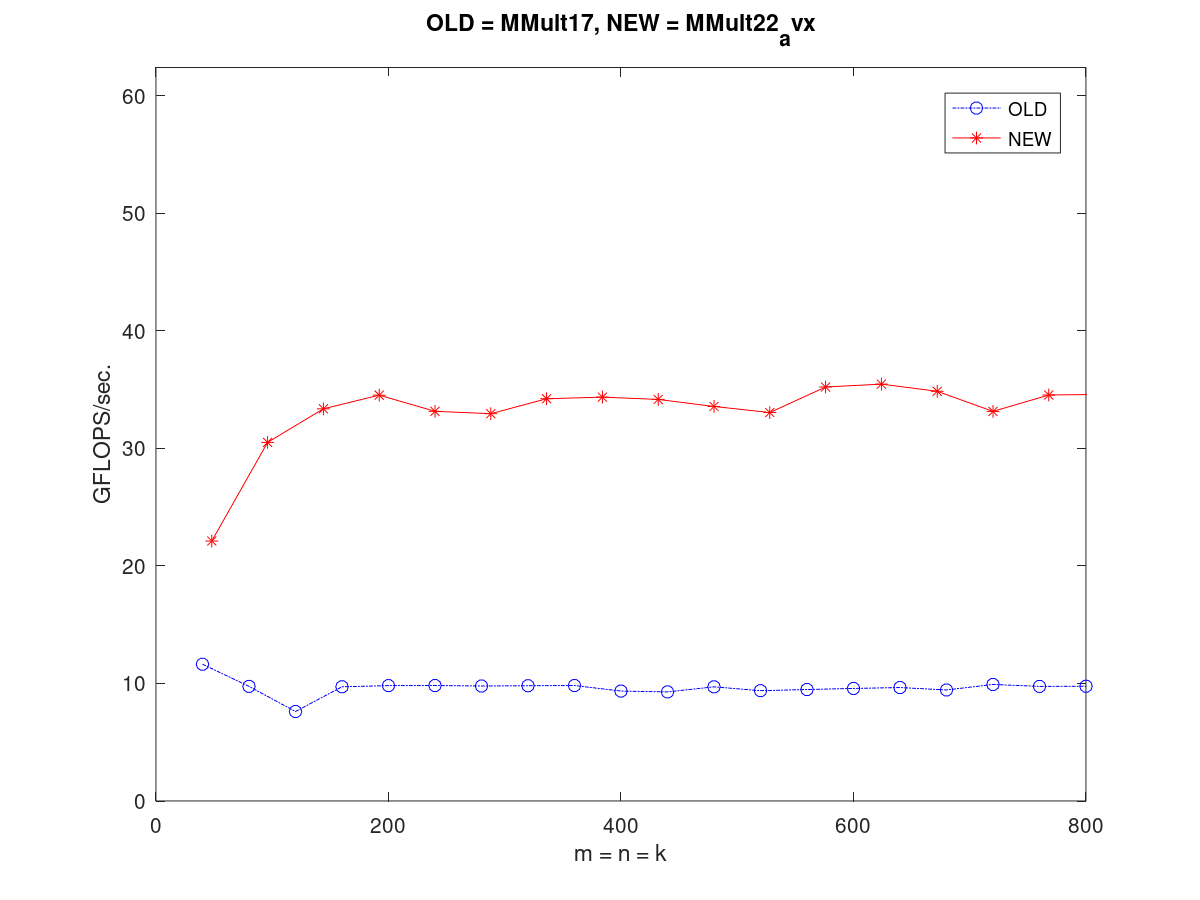
- 7. 接下来的版本测试了
MMult22_avx3_8x6 指令改为 8x6
MMult23_reordering 指令load数据和计算交替进行
MMult24_asm2 改为汇编指令
MMult25_asm_unroll2 汇编指令进一步unroll循环
MMult26_prefetch 使用汇编的cache 预取
目前可能是因为有瓶颈存在于其他地方,所以gflow都没有提升也没有下降
GPU 下 GEMM
这部分也参考了白牛的知乎cuda 入门的正确姿势:how-to-optimize-gemm
- 1. v2 使用shared memory
- 2. v3 跨步循环减少 BLOCK数量
- 3. v5 内存对齐
- 4. v6 warp 优化
- 5. 【TODO】后续内容 7 8 9
GPU 下 卷积
- 1. v1 shared memory 并未加速
- 2. v3 纹理并未加速
4. 实验结果
结论:目前优化gemm有如下通用方案
- 1. 数据排布对内存访问的顺序很关键
- 2. 利用lcache很关键
- 3. simd 指令很关键
- 4. 指令排布
- 5. 预取
- 6. cuda 下减少开启block的数量
- 7. cuda 下利用warp原语
5. 总结和展望
总结:
- 挖掘硬件特性的利用极限远不止于此
- 能不能更智能?
后续
- 卷积的 Winogard Img2col Qnnpack 实现
- 稀疏矩阵求解,和混合精度求解
- SIMD 指令的精细研究排布
- CuAssemble
- Arm 下 powerperf
6. 参考资料
GEMM 相关
- 1. 从分块到汇编指令排部 https://github.com/flame/blislab
- 2. BLISlab 前三段的解释 https://github.com/flame/how-to-optimize-gemm/
- 3. 以上内容的补充解释 https://zhuanlan.zhihu.com/p/65436463
- 4. 混合精度综述 https://zhuanlan.zhihu.com/p/66958390
- 5. Ncnn https://zhuanlan.zhihu.com/p/457443433
CUDA GEMM
- 1. cuda 入门的正确姿势:how-to-optimize-gemm
- 2. Cuda ConvNet https://code.google.com/archive/p/cuda-convnet/
- 3. Caffe https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
- 4. Cutlass
- 5. Mega Conv https://zhuanlan.zhihu.com/p/372973726
- 6. Gemm 到 Cublas https://zhuanlan.zhihu.com/p/518857175
完整自定义算子项目
- 1. 自定义精简版推理库 https://github.com/zjhellofss/KuiperInfer
- 2. Ncnn https://github.com/Tencent/ncnn
- 3. Faster-transformer
PERF工具
混合精度
- 1. gemmlowp https://github.com/google/gemmlowp
- 2. Qnnpack https://engineering.fb.com/2018/10/29/ml-applications/qnnpack/
- 3. Nvidia Apex https://github.com/NVIDIA/apex 混合精度
- 4. 半精度模拟单精度 https://arxiv.org/abs/2203.03341 作者博客 https://enp1s0.github.io/
量化
数值计算
- 1. 混合精度求解器 https://www.bilibili.com/video/BV1LB4y1p7QP/
- 2. Quant-taichi
体系结构
- 1. L1 L2 https://zhuanlan.zhihu.com/p/488531131
- 2. Cuda 体系结构的逆向分析 https://zhuanlan.zhihu.com/p/166180054 CuAssemble https://zhuanlan.zhihu.com/p/348234642