Starofus
你好呀,我是Sans
【HPC 04】用Cuda实现和调试一些常见算法
2023-4-1
高性能计算的整体蓝图,Cuda openmp SIMD指令 TVM 和 高性能计算
代码:https://github.com/mrzhuzhe/riven
1. 概述
由于之前深度学习,物理仿真,渲染等都需要用到高性能计算,cpu/gpu下并行编程,所以最近做了一些cuda相关的练习
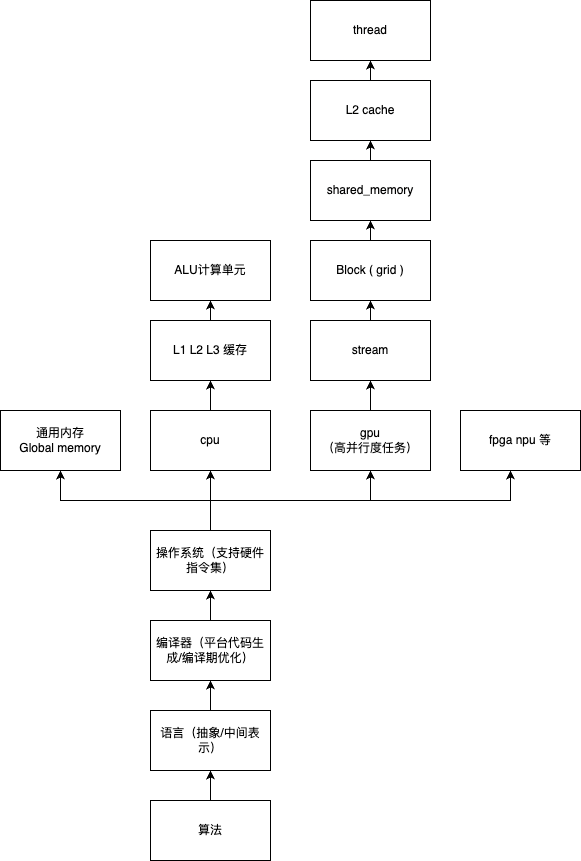
为什要有并行计算?:
- 理论上可以不断进行算法层面的优化,减少算法复杂度来提升程序性能(实际上不行)
- 单线程的处理效率在2000年左右就到了瓶颈,目前cpu都是单cpu多核心,单线程程序的执行效率有限
- 针对单一领域算法的fpga缺乏范用性,你不能指望硬件的内存线程完全配合你的应用来
- 现在的gpu并行计算模型,和应用,大行其道
- 其实现在gpu的性能也到了瓶颈 只能通过改gpgpu的硬件 tensor core NPU 如苹果的core ml来针对领域应用优化性能
- cpu gpu的(我猜是电路设计的原因)指令集一般都支持指令向量化(arm_neon x86 的 sse vvx)一次执行多条(4/8)条计算指令(指令可以并行执行)
因此:
在算法层面:
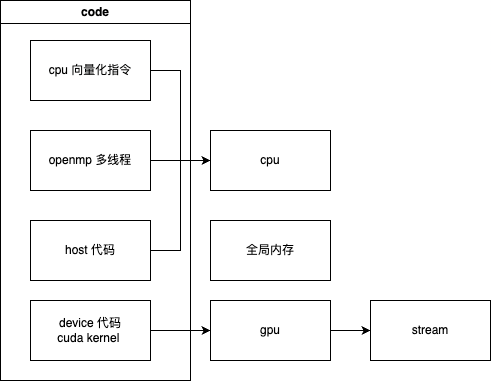
- 我们只能用并行编程的模型来在cpu和gpu中并发的开启多个线程来coding,所以需要考虑数据竞争的情况,需要用到锁,障碍,原子操作等处理竞争关系
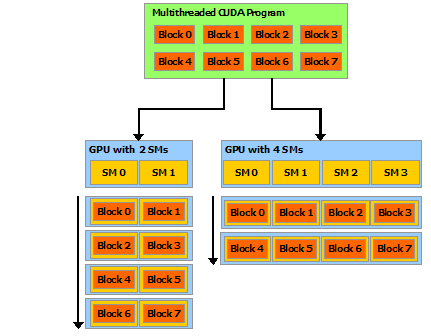
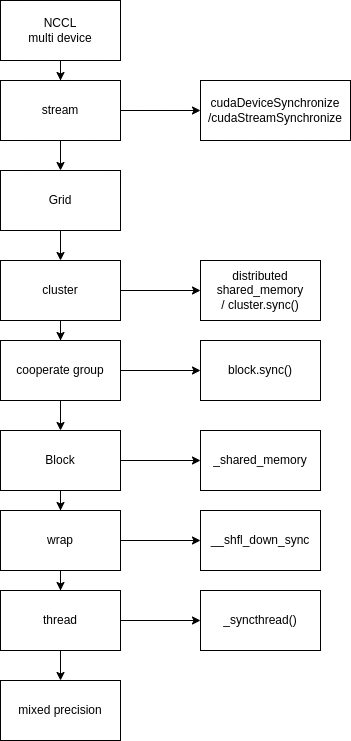
- gpgpu的和cpu的并行编程模型不太一样,增加了grid block thread warp 同步 等概念,算法本身需要针对硬件环境
- 针对精度要求可以用半精度或者更小精度,配合指令向量化一次执行多条计算(取舍)
- 用特定数据结构aos soa等配合cpu缓存和预取机制
在内存层面:
- 减少内存读取
- 提升内存读取的局部性利用CPU GPU的L1 L2缓存
- 利用默认的缓存prefech机制
- 利用硬件特制的内存,如N卡的Block shared_memory
- 还有一些特制的只读内存如cuda 的 texure 可以减少读取开销
还有其他办法吗
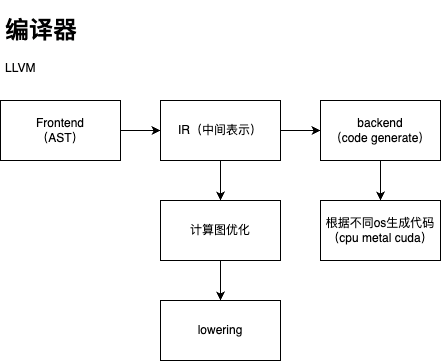
在编译器层面
- 计算图表示的层面优化:TVM代表的算子融合 替换
- 多面体优化 深度学习编译器有哪些有价值的研究方向和参考文献? https://polyhedral.info/
目前:
我做了什么?:
- cuda的练习
- neon指令集的练习
2. 相关工作
最开始想弄cuda和编译器是由于看了taichi的分享,taichi用python前端,可以选择生成cpu还是gpu平台的代码,通过vulkan实现了跨平台metal和cuda
并且在稀疏数据结构上做了一些功夫,让代码执行效率几乎不输原生cuda
这样做的好处是代码不用写c++可以更专注于更上层的抽象,默认跨平台还有非常不错的性能
但是坏处或者说取舍也十分明显
为什么?
- 1. 虽然给python加了语法糖,支持并行化,但是还是取消了指针和细粒度的线程控制
- 2. 虽然用field实现了极高性能的内存结构,稀疏数据结构,但是还是取消了细粒度的内存控制
- 3. 跨平台非常好用,但是对平台的支持完全依赖于taichi内部实现,不保证能完全利用该平台的新特性
所以类似的工作如LuisaRender/Compute都是走了这个路线,只是“取舍的程度不同”
这次我们从cuda的角度来看:
Cuda提供了哪些功能呢?
- 1. cublas cudnn等计算库,高效实现的矩阵计算,张量存储等常见算子和功能的封装
- 2. nsight compute 等新能检测工具
- 3. 迭代了无数版本的cuda硬件,和用户社区中的无数资料
- 3. cuda 编程模型,让我们给予他能开发各种应用 cuda programming guide
3. 实验设计
此处演示,代码都在riven下
- 1. openmp
/openmp
- 2. neon 指令集
/neon
- 3. Cuda 编程模型: 归并/扫描
/cuda_test/warp ./build/reduction
Time= 4.202200 msec, bandwidth= 15.969936 GB/s
host 16777216.000000, device 16981248.000000
./build/reduction_shared
Time= 0.524270 msec, bandwidth= 128.004395 GB/s
host 16777216.000000, device 16777216.000000
./build/wp // block 跨步循环 + warp 原语 和 balance balance_opt 差不多
Time= 0.262390 msec, bandwidth= 255.759979 GB/s
host 16777216.000000, device 16777216.000000
是否有diverge
大部分为不执行(diverge)代码和shared相同
Time= 0.514730 msec, bandwidth= 130.376831 GB/s
host 16777216.000000, device 16777216.000000
大部分为执行
Time= 0.419230 msec, bandwidth= 160.076477 GB/s
host 16777216.000000, device 16777216.000000
./build/cg // 协程组 默认 block level 似乎影响不大
Time= 0.245920 msec, bandwidth= 272.889008 GB/s
host 16777216.000000, device 16777216.000000
pipline 下还有一个grid level cg 用了 cudaLaunchCooperativeKernel 待研究
Time= 0.092800 msec, bandwidth= 723.155884 GB/s
host 16777216.000000, device 16777216.000000
./build/atomic_blk // 用 block level cg 在一个block内归并 再把block结果atomic add到全局 , 默认atomic速度非常慢比native实现还慢五六倍
Time= 0.248800 msec, bandwidth= 269.730164 GB/s
host 16777216.000000, device 16777216.000000/cuda_test/pipline
手动设置stream 优先级等,似乎效果不明显
MPI 部分目前还没有做
还有一些常见操作比如
卷积 / 扫描 / 快排等
多体问题 - 向量化 - 4. Cuda 只读内存(在流体模拟里)
- 5. Cuda 常见库:实现一个cuda神经网络【TODO】
/cuda_test/nn
- 6. Cuda 实现拉格朗日流体模拟【TODO】
/cuda_fluid
- 7. 混合精度【TODO】
- 8. TVM 入门练习【TODO】TVM Relay Relax 额外资料:机器学习系统
- 9. 用nsight compute来performance gdb debugger
4. 实验结果
- 内存往往昂贵于计算
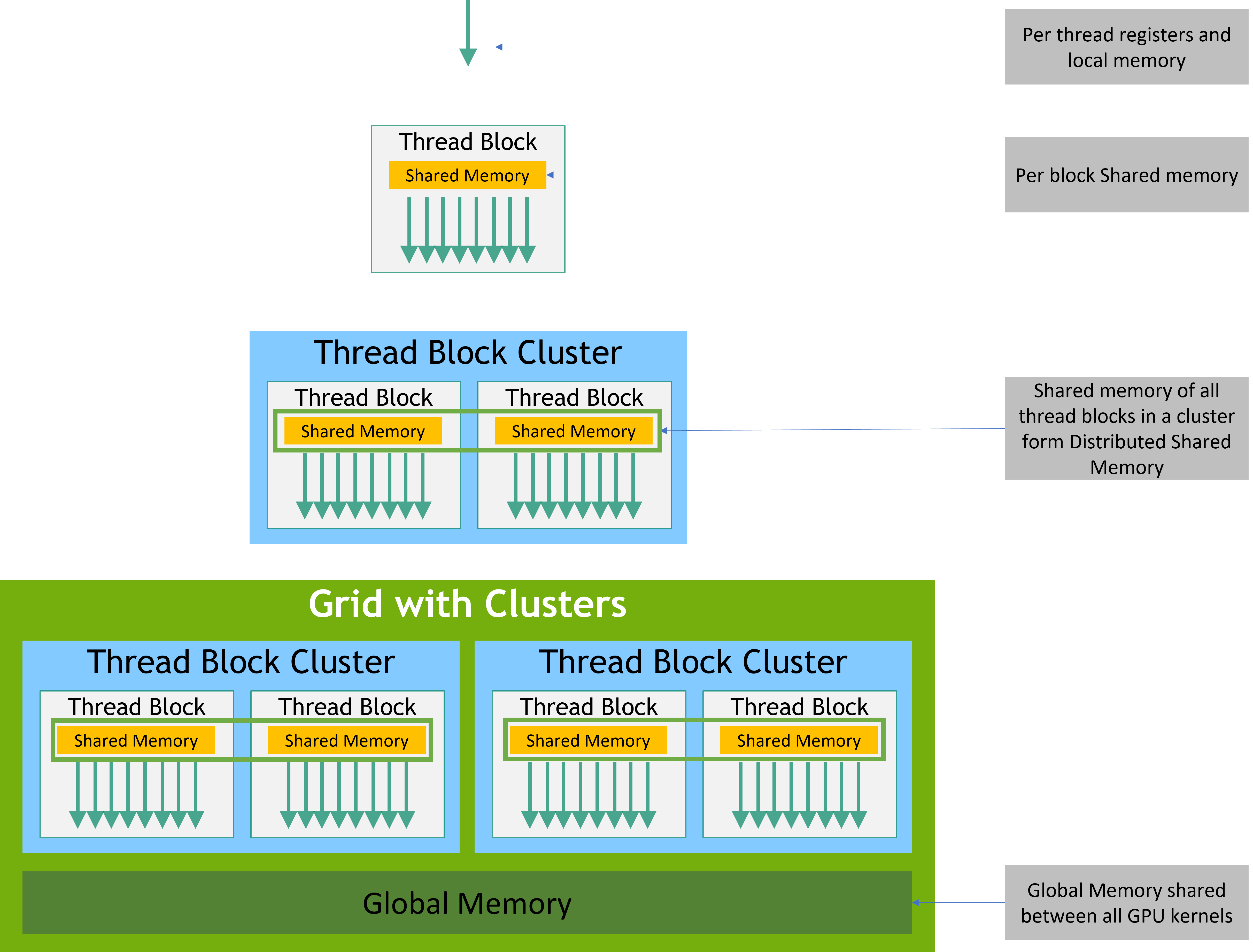
- L1 L2 缓存和prefecth机制影响很大(内存局部性)
- 低精度量化对减少内存开销影响很大
- 向量化指令集速度很快,但是各个平台不兼容难以统一处理
- 最优化循环的gridsize blocksize,协程组,warp diverge bank conflict其实对结果的影响没那么大
- cuda sample 中的helper 封装了 cuda error code 转文字 和 timing记时的函数
- cuda 有些比较偏门的功能和概念 比如 unified memory 和 cluster 也不知兼容性和实际性能如何
一些bug
5. 总结和展望
- 后面会自己实现gemm对比效率
- 熟悉cuda的半精度和warp源,加深对cuda编程模型的理解
- 解决Nsight compute 不能跑的一些bug,测试和熟悉trace profile的详细功能
- 会加紧练习光线追踪和物理渲染的其他应用
- 会加紧了解编译器相关知识,针对各个平台的实现目前还在蛮荒时代,需要做一些自动优化的工具
- 后面参考和学习fastertransformer oneflow tensorrt 之类的实现
- openmpi nccl RDMA megatron deepspeed等?
- SOC RISC-V 微架构等?
6. 参考资料
- 1.《Learn CUDA Programming》Code Example CUDA 入门书
- 2.《并行编程方法与优化实践》第二版 (刘文志)
- 3. 高性能并行编程与优化 from 双笙子佯谬 B站视频
- 4. 强烈推荐 Oneflow团队的 Gaintpandacv博客涵盖指令集/编译器/各种backend实践
- 5. 陈天奇的MLC课程 https://mlc.ai(文档和作业) 和 B站视频